Hyperparameter Tuning
hyperparameters.RmdNote that there is no universal way to assess the best number of topics (num_topics) to fit a set of document, see this post.
Preprocess
As stated in table 2 from this paper, this corpus essentially has two classes of documents. First five are about human-computer interaction and the other four are about graphs. Therefore a process to assess the best number of topics to apply to a corpus should return 2.
library(gensimr)
data("corpus", package = "gensimr")
texts <- prepare_documents(corpus)
#> → Preprocessing 9 documents
#> ← 9 documents after perprocessing
dictionary <- corpora_dictionary(texts)
corpus_bow <- doc2bow(dictionary, texts)
tfidf <- model_tfidf(corpus_bow, id2word = dictionary)
corpus_tfidf <- wrap(tfidf, corpus_bow)Tune
We can run multiple Latent Dirichlet Allocation models given different number of topics then assess which is best using the perplexity score.
models <- map_model(
num_topics = c(2, 4, 8, 10, 12),
corpus = corpus_tfidf,
id2word = dictionary
)
plot(models)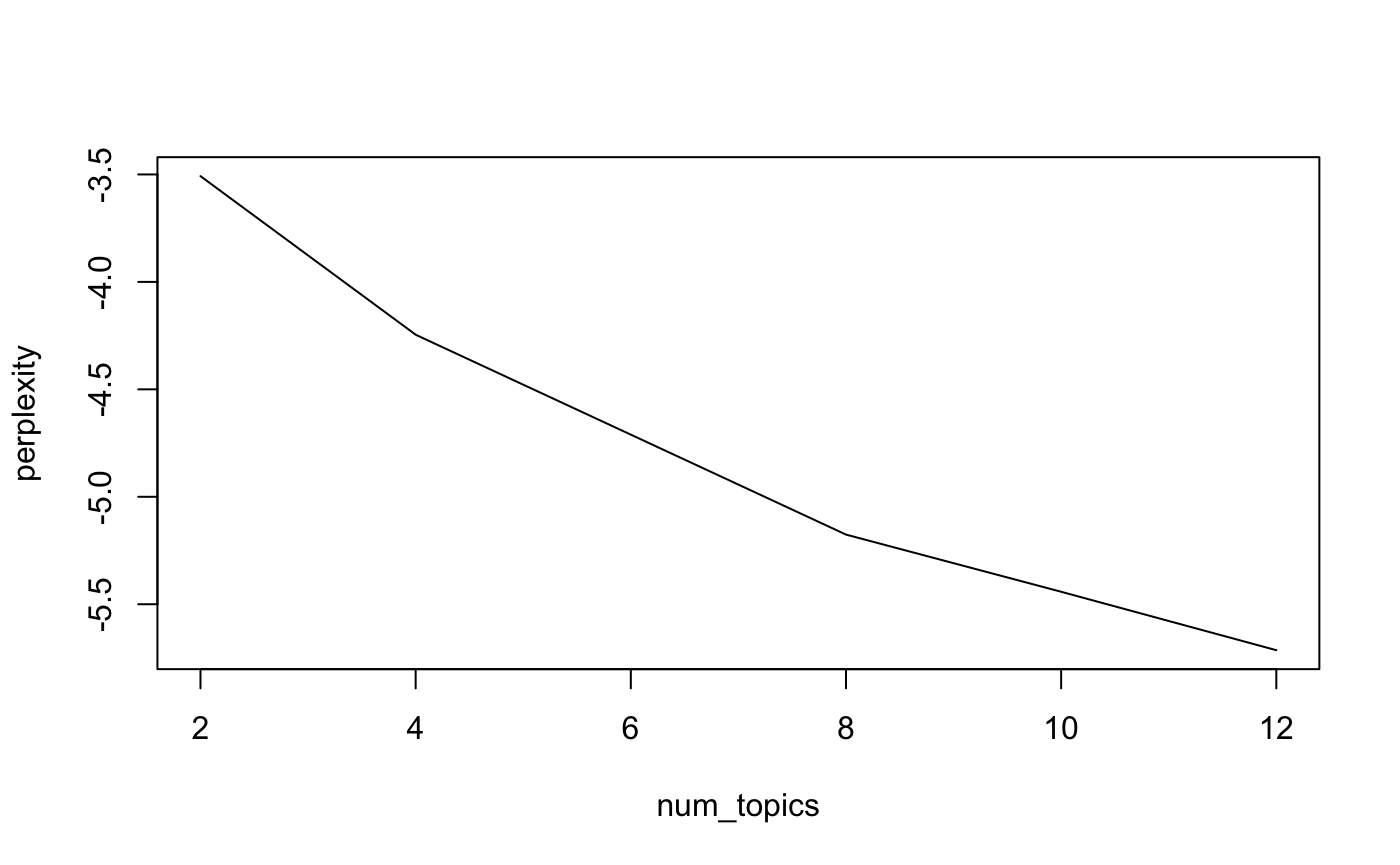
get_perplexity_data(models)
#> # A tibble: 5 x 3
#> num_topics perplexity model
#> <int> <dbl> <list>
#> 1 2 -3.51 <gns...LM>
#> 2 4 -4.25 <gns...LM>
#> 3 8 -5.18 <gns...LM>
#> 4 10 -5.44 <gns...LM>
#> 5 12 -5.71 <gns...LM>